One of the unique feature of VMware’s Operations Management solution has been the analytics engine which has the ability to learn the behaviour of every metric and create a dynamic threshold which reflects the usage patterns. These usage patterns are the key to register anomalies or abnormal behaviour of a metric which helps in proactive detection of an issue which might hit that metric source.
While all this sounds fantastic, one thing which always worried me was the one track approach of this learning behaviour. In other words, if you have an environment which has issues and you drop in vCenter Operations Manager 5.x in the same environment, chances are that you would wait for a period of 1 or 2 months before looking into the alerts shown by vCenter Operations Manager. In usual terms this is defined as a cooling off or first time collection period and we tend to sit back and relax while the analytics engine is crunching away the numbers.
A risk with this approach is that you might end up telling vCOps 5.x that some of the issues or bad behaviour is actually a normal behaviour in your virtual infrastructure, by not taking any actions against the early alerts you get from the system. While data collection for a longer period is good to learn cyclical behaviour, it is important that you iron out all these early alerts which you get from vCOps 5.x to ensure that the system is not learning bad behaviour as usual or normal behaviour. While I say this, I must also admit that doing this as soon as you deploy the product and assuming you don’t have any expertise might be a difficult task.

With the release of vRealize Operations Manager, the product engineering group has done a great job of taking this weakness of the earlier versions and making it a strength of this new release. This was done by using the years of knowledge base created by troubleshooting VMware environments, feeding it into the new release and churning out RECOMMENDATIONS to solve issues which are detected as per the recommended best practices. This recommendation engine ensures that you get immediate recommendations about the issues which vROps thinks are not normal and you should act upon them either using your own intelligence or on the advice given by this recommendation engine itself.
Now this sounds ABSOLUTELY AWESOME. We all know that the proof lies in the pudding, hence without further a do, let us see what happened as soon as I deployed vRealize Operations 6.0 in my lab and migrated the data from the earlier install of version 5.8.2.
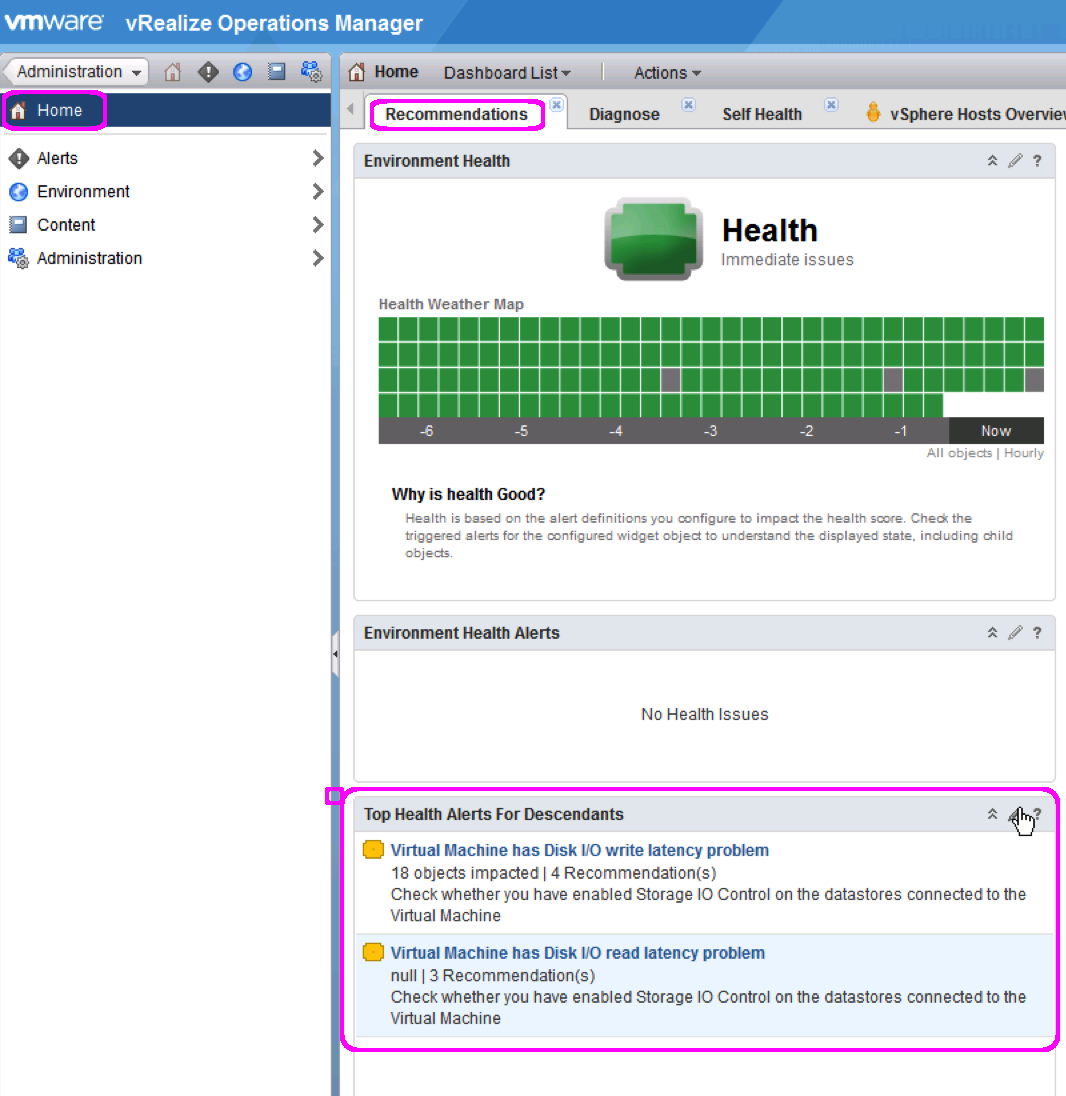
As soon as you launch vROps 6.0, you will be automatically directed to the Recommendations Dashboard. Here is the screenshot from my lab which shows this dashboard.
You will immediately notice that I have got a bunch of issues highlighted in my infrastructure. I will click on the message which says – “Virtual Machine has Disk I/O write latency problem” and what do I see.
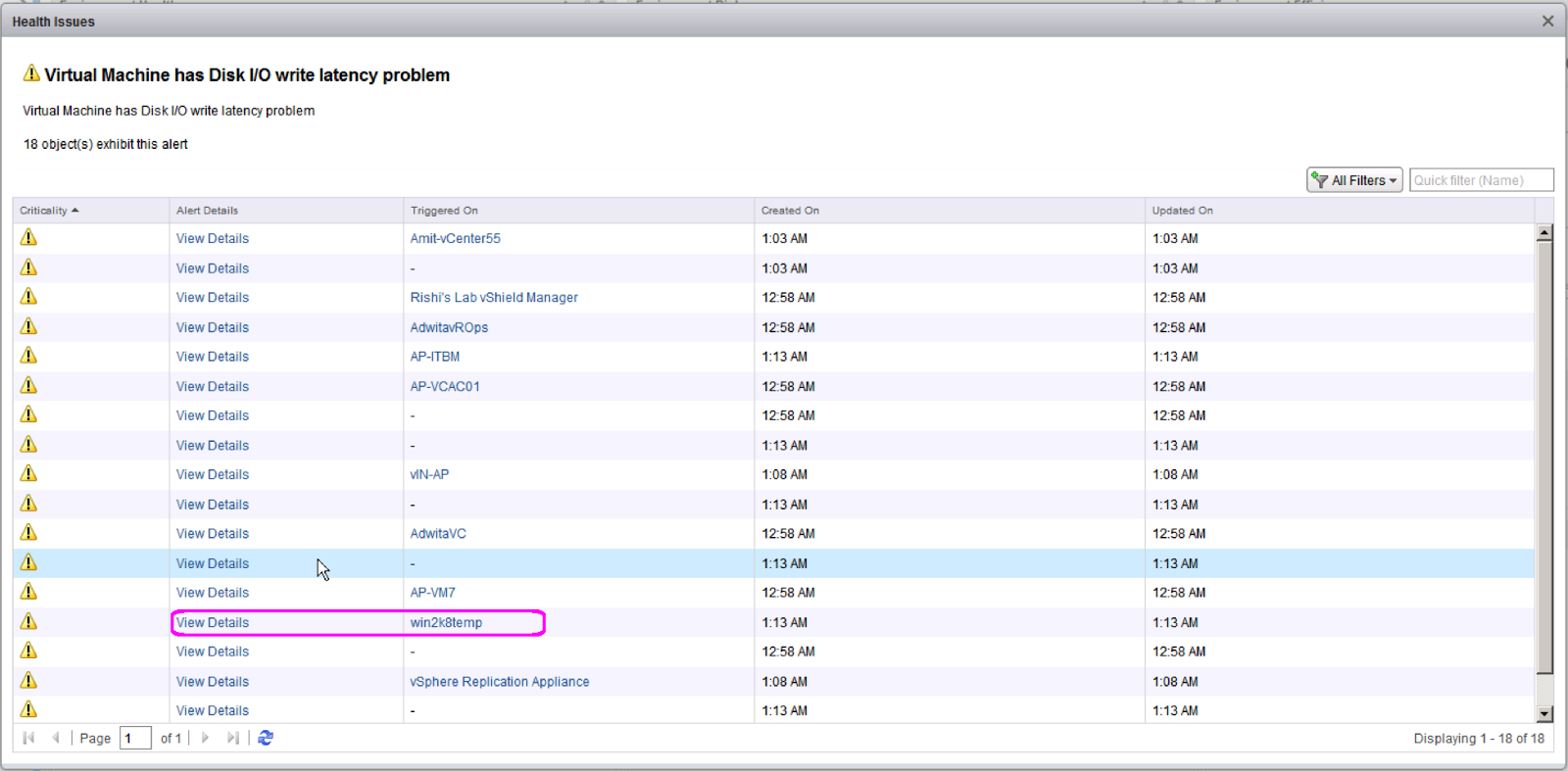
I see all the virtual machines which are experiencing Disk I/O read latency. In my case I have a single datastore running all the virtual machines hence the latency. As my next step, I will click on one of the virtual machine (win2k8temp) to see what recommendations I get for this virtual machine.
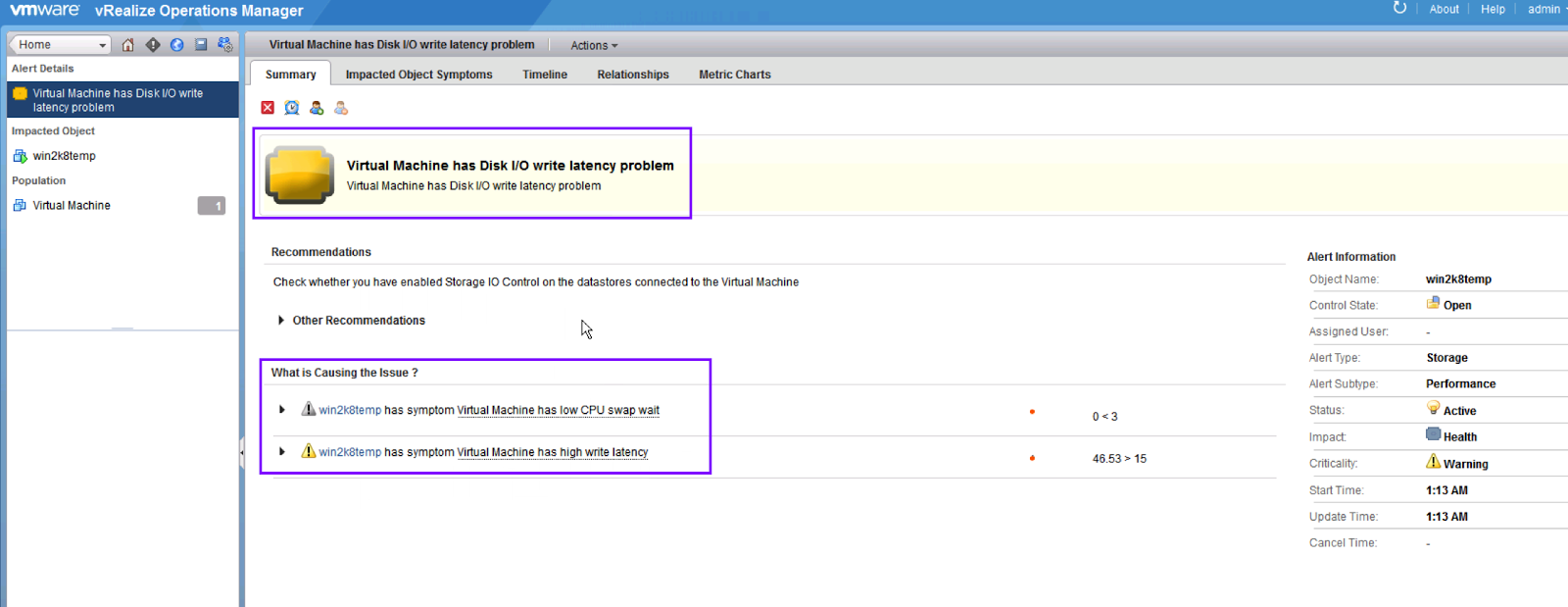
I can immediately see a recommendation coming out of the system stating that
I should enable Storage I/O control to introduce quality of service on the datastore. This will ensure that I can provide the required IOPS to virtual machines which are important to me. I can also see that the VM has low
CPU swap wait indicating towards another symptom which could lead to a performance issue.
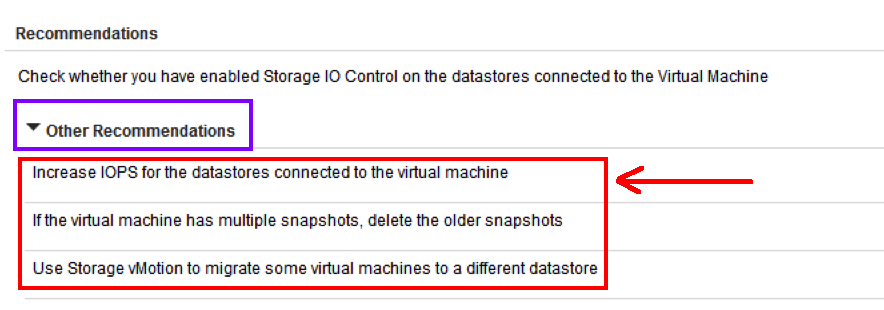
If you notice, their is another option to click on which says “Other Recommendations”. Let us expand that option to see if we have more recommendations from the tool about the issue.
The other recommendation shows some more options which could help you resolve the issue. If you notice, these recommendations are intelligent in nature and are based on recommended best practices. This recommendation engine is smart and as I said based on experience. This is truly next generation. I almost forgot to tell you that you can write your own recommendations, and if are using third party management packs, then they would come with their own recommendations for devices / applications etc you are monitoring using those management packs.
With this, i will close this post. Hopefully you will enjoy the read and implement some of the learnings within your operations manager deployment. Will come back soon with deep dive into other new features.
Till Then….
Share & Spread the Knowledge


Hello Sir,We are unable to Apply interaction between DATASTORE & Virtual machinewill you please share any solution for that
LikeLike
Interactions only happen between widgets. Could you please share more details on what you are trying to achieve?
LikeLike