In the series on vRealize Operations, I wrote about the Architecture of vRealize Operations Manager which allows you to have Master and Replica nodes in a vROps Cluster. This not only allows you to distribute the adapters or solutions to more than one collectors present on each host, but also gives you resiliency in case the Master Node in the cluster fails.
With this post, I will actually share a failure which has been seen in my lab because of a couple of services failing on the master node. This resulted in a fail-over and the Replica switched over to become the Master Server. All this is possible because just like the previous releases, each and every service on your vROps nodes in being monitored by vROps itself.
Let me give you a brief description of my lab before I begin:
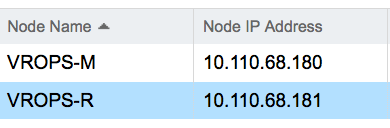
As you can see in the screenshot from my lab, I have a Master Node and a Replica Node. Since the past few days, when I tried accessing my vROps product UI through the Master Node IP address, it gave a Page Cannot Be Displayed. I immediately switched over to the other IP to see if I was able to access. As per the product behaviour, I can access the solution through any node of the cluster and I was able to achieve that without issues.
Today, I thought of looking at the issue with my Master Node and all I had to do was to click on a RED box on the recommendations page. Let me share that through a screenshot:
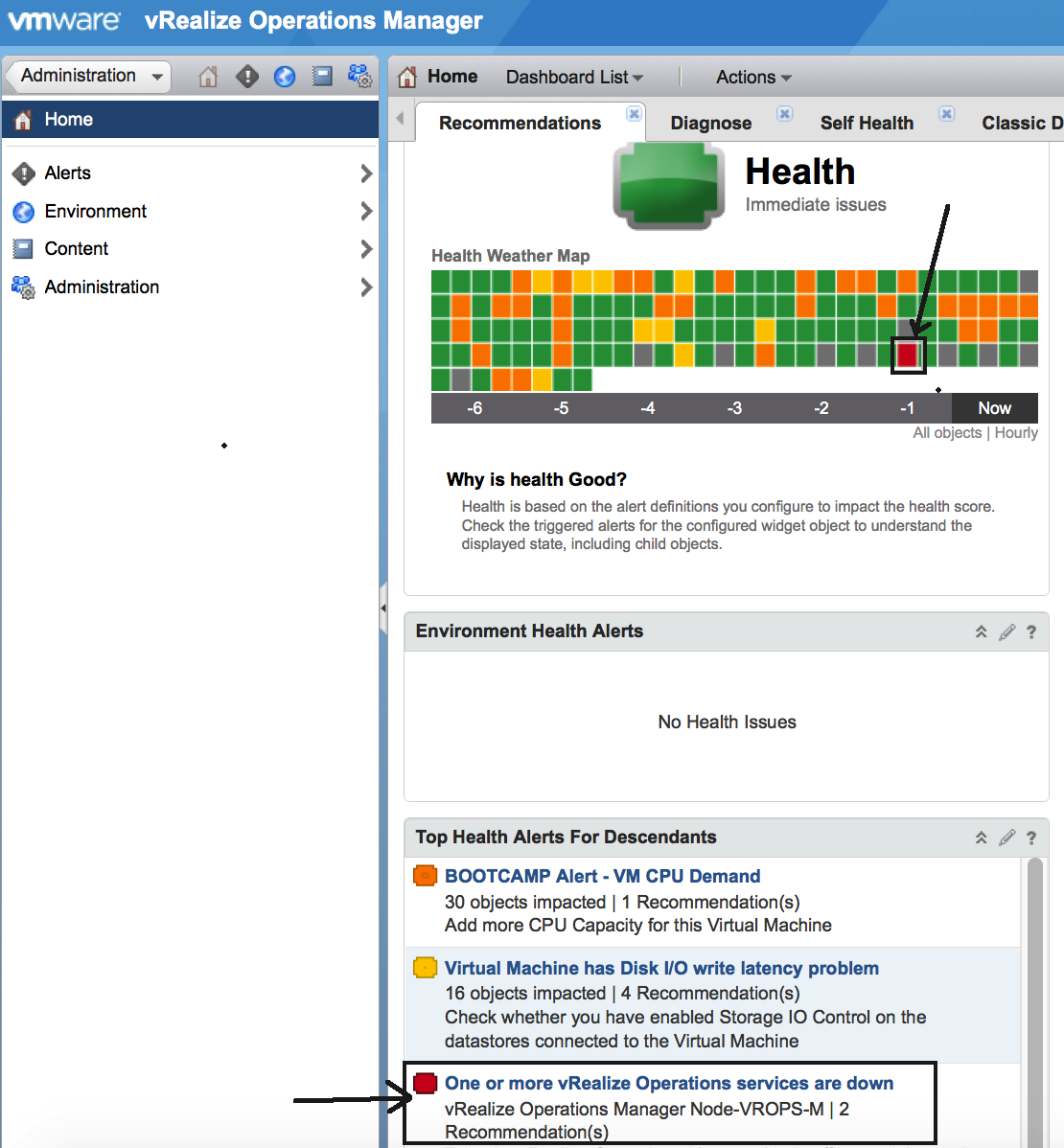
You can see that I have a red object on the Heat Weather Map and if I look down, I can immediately see an Alert for the the Master Node about services being down and 2 recommendations. Let us see what are the recommendations by clicking on this Alert:
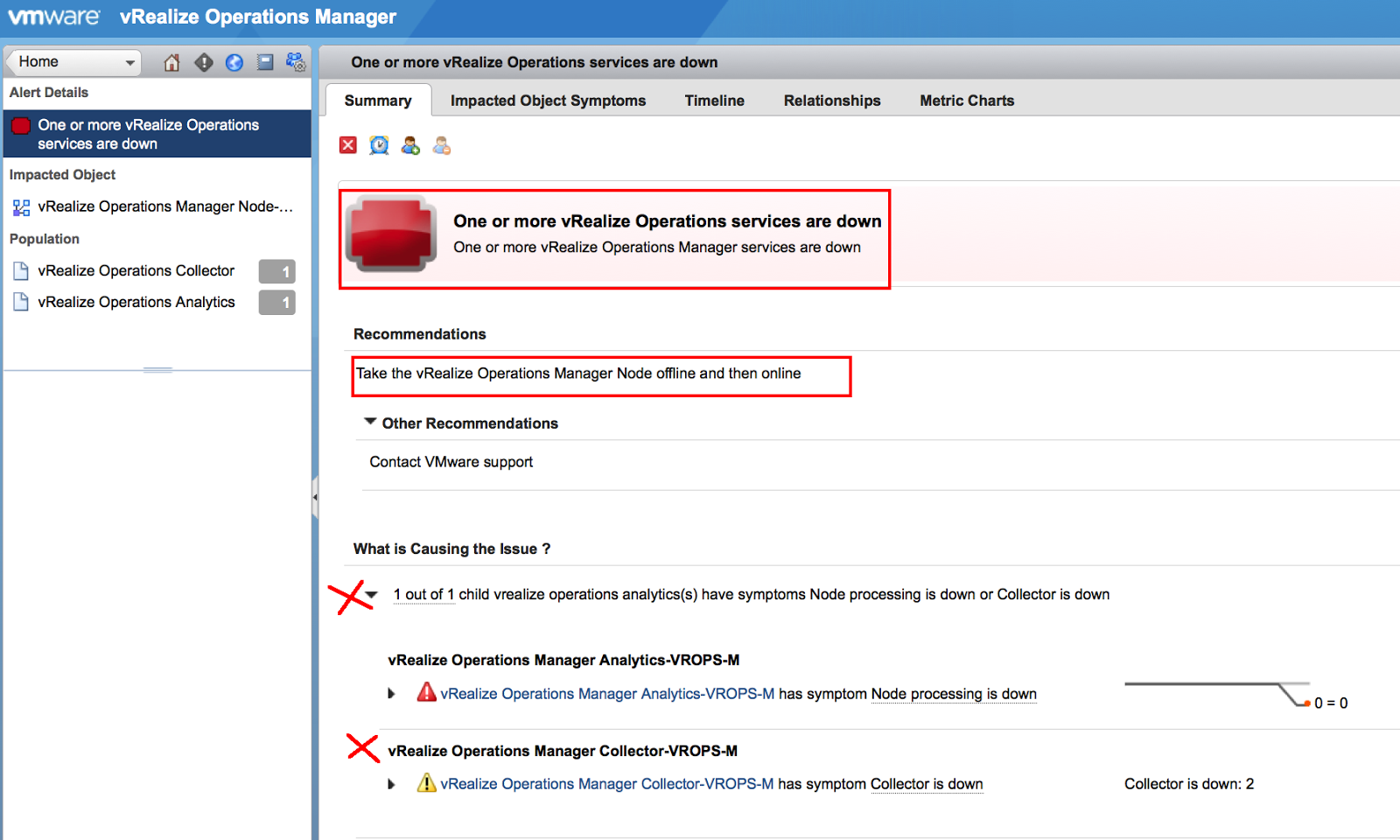
Here, you can see that the Node Processing and Collector services are down and hence we are getting 2 recommendations to resolve this issue. One is to take the node offline and then bring it back online. The other option is to visit VMware Support. We could have also reached this screen, or could have directly jumped on a screen which monitors the entire vROps cluster by clicking on:
Home -> Environment -> vRealize Operations Cluster
Here we can expand the cluster and see all the nodes and services associated with each node. Let us see this in a screenshot:
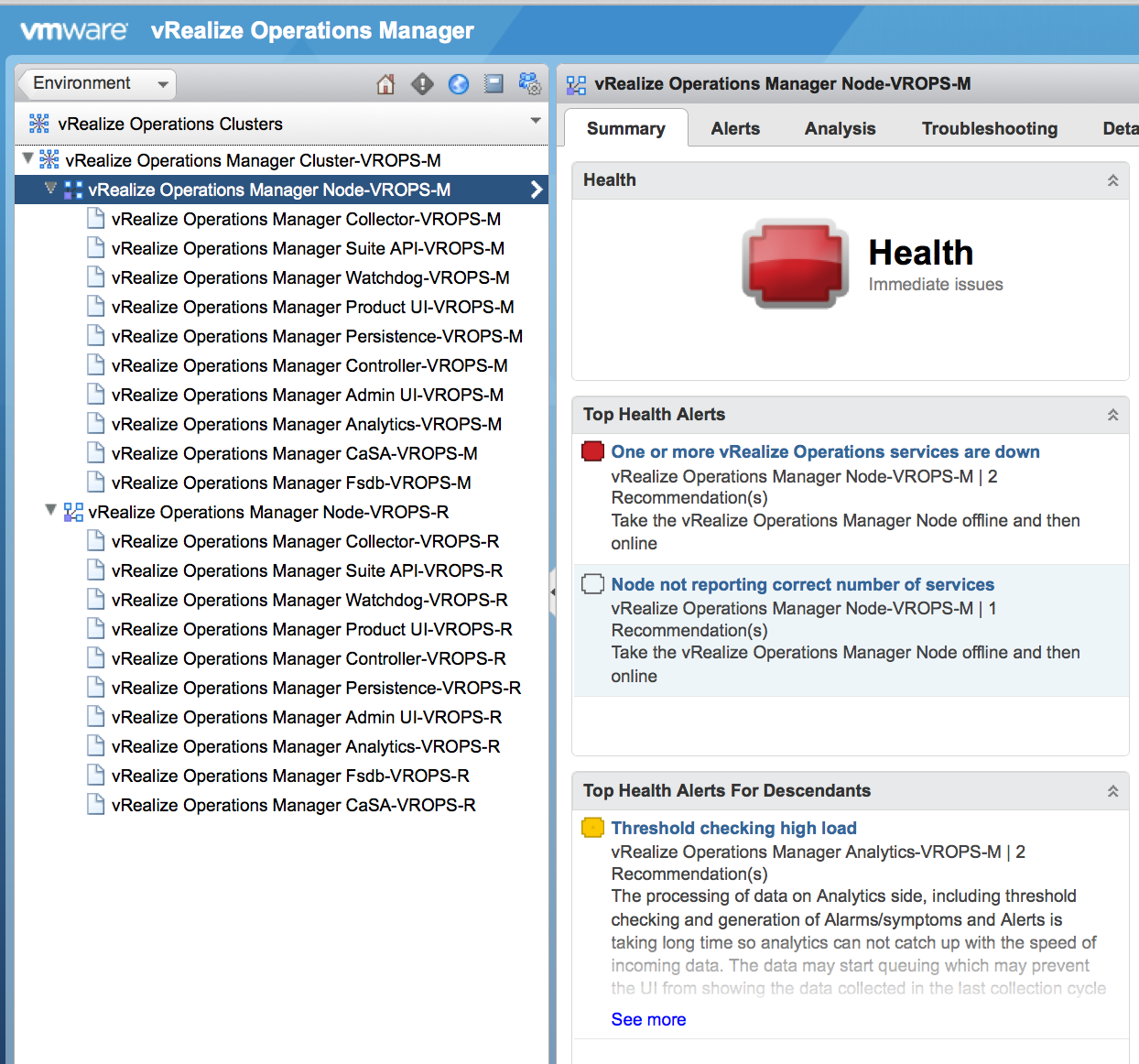
Here you can look at all the services and their health individually. Instead of going through these services, we will try to follow the recommendation given by the tool to make the affected node offline and then back online. Let us go into the cluster management and see the current state of the cluster:
Click on Home -> Administration -> Cluster Management
Now you can see that the Replica Node has become a Master Node and vice-versa. We can select the VROPS-M node here and bring it offline.

As soon as I tried to take the host offline, I got an error that the Operation has failed and I should contact VMware support. Since, it’s just a lab I will go ahead and restart the VROPS-M node from the vCenter Server and after a few minutes I was able to login to the Master Node IP address. Once I login into the Product UI, I can see that the resources have been distributed between both the clusters and the data gathering has started to work again. One thing to notice is that, after a failure the Master and Replica have switched over roles.

Voila, the issue seems to be fixed and I have all the nodes in a working state with objects and Metrics both shared between the nodes for a faster collection. If you go to the main recommendations page from where it all started, you would notice that that box will now turn green and you are good to go as the entire solution is up & running.
Hope this helps you in configuring your vROps clusters with confidence and a complete understanding of how the clusters are monitored and fail-over process works.
Share & Spread the Knowledge
