
The challenge with this requirement is around the time factor. Different workloads can have different impact of running on snapshots. For instance a web server running on a snapshot might not be impacted much from a performance standpoint, however an Oracle database VM running on a virtual disk snapshot would definitely not be a happy camper at the time it’s running database transactions. Just to be clear, we are discussing vSphere snapshots here and not any other snapshot technologies. With vROps, there is no metric today which tracks the snapshot on the basis of time. While there are metrics which define the age of the snapshot, using these metrics for alerts become impossible, as for each snapshot a new directory is created, under which a snapshot drive is created and it increments in size. As soon as you delete this snapshot and take a new one on vCenter, vROps creates a new directory for this new snapshot and hence it is difficult to track hundreds of directories which keep changing, specially in an environment where snapshots are heavily used.
In order to overcome this situation, we will create a new alert. If you are new to Alerts in vROps, I would highly recommend that you watch this episode of my yearly long Webinar Series to get well equipped about vROps Alerts and Symptoms.
We will start by creating a new symptom & an alert definition:
1- Login to vROps with credentials having rights to create new Alerts/Symptoms (admin credential would be nice).
2- Click on Content -> Symptom Definitions. You will be under the metric/property symptom definitions category by default.
3- Click on the + sign to add a new Symptom.
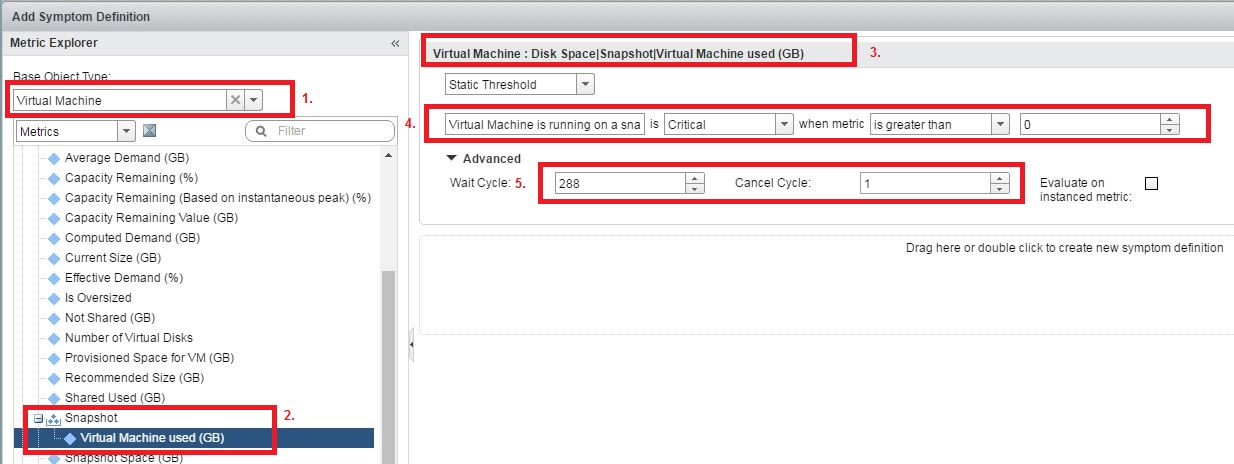
4- Here is how you will define the new symptom. Refer to the screenshot for more details:
- Base Object Type : Virtual Machine
- Metric Name : Disk Space|Snapshot|Virtual Machine Used (GB)
5- Double click on this metric to add it to the right pane where we will describe this symptom.
6- Here is how will you provide the details:
- Static Threshold
- Symptom Definition Name : Virtual Machine is running on a snapshot for more than 24 hours
- Critical
- Condition : When Metric is > 0 (This is the size of the snapshot)
- Advanced : Wait Cycle – 288 (Each cycle is 5 minutes, hence the total minutes we will check for this condition is 1440 minutes which is 24 hours)
- Advanced : Cancel Cycle – 1 (Once the condition is false, the alert will be cancelled in 5 minutes)
7- Click on Save to save this symptom. Once done we will create a new alert using this symptom.
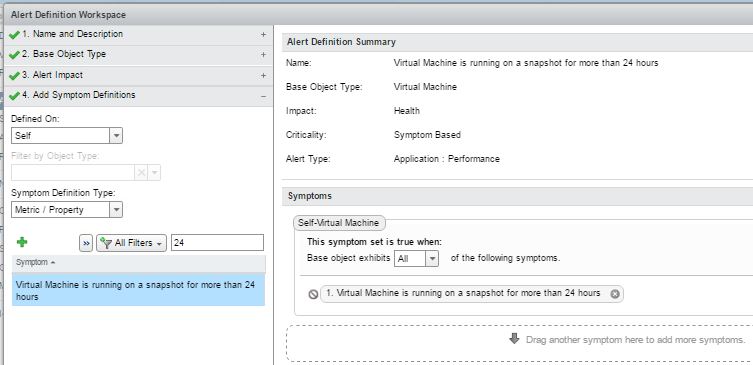
8- Click on Content -> Alert Definitions. Click on the + sign to add a new Alert and provide the following details:
“1. Name & Description”
Name – Virtual Machine is running on a snapshot for more than 24 hours
Description – This alert will trigger when a virtual machine is running on a snapshot for more than 24 hours.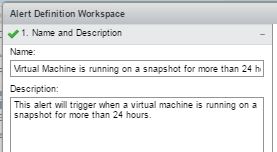
“2. Base Object Type”
Virtual Machine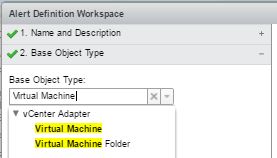
“3. Alert Impact”
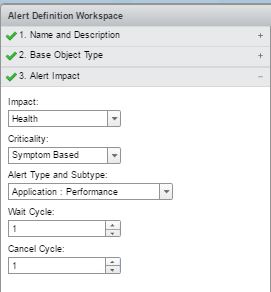
“4. Add Symptom Definitions”
Symptom Name : Virtual Machine is running on a snapshot for more than 24 hours
“5. Add Recommendations”
Add any recommendations from the available list or create your own.
9- Click on Save. This will create a new alert definition and this alert will be enabled on the default policy by default.
Please note that the Wait Cycle will start counting as soon as you create this alert definition, hence this alert will take atleast 24 hours to trigger. If you have VMs with snapshots (more than 24 hours old) in your environment, don’t expect the alert to trigger immediately. The countdown to 24 hours will begin when you enable the alert in the policy.
You can see that we used a Time Based symptom to solve a key problem which emerges and could lead to a number of issues in a virtual environment. Hope this will give you ideas on how you can create more time based alerts using metric based symptoms.
