Hope you are enjoying the What’s New with vROps 6.6 Series. I am having a great time writing this, since my experience as a user of vROps has completely turned around with this release. In this post, we will continue talking about the rich & use case driven out of the box content available in the form of dashboards.
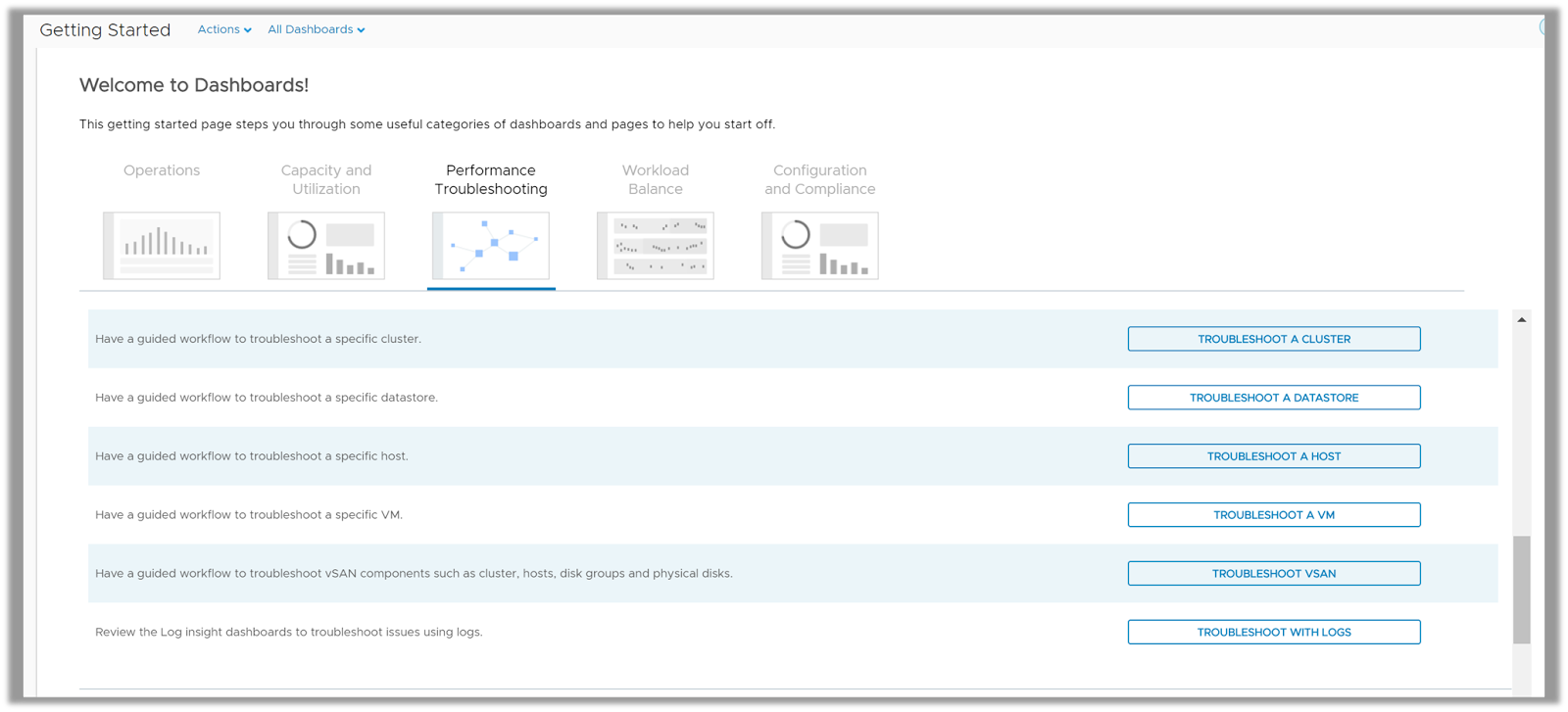
The Getting Started page in the product acts an anchor for showcasing all the use cases. The focus of this post would be on Performance Troubleshooting.
Here is how Performance Troubleshooting shows up on the Getting Started Page:

The Performance Troubleshooting category caters to the administrators responsible for managing the performance & availability of the virtual machines running in the virtual infrastructure. This category runs your through a guided workflow to answer questions which will help you with the troubleshooting process. The dashboards in this category identify and isolate problems that may impact your applications. They provide a line of sight into the full stack to isolate and identify the root cause quickly.
Key questions these dashboards help you answer are :
• Is application performance impacted due to virtual infrastructure?
• Are noisy neighbors impacting multiple virtual machines and corresponding applications?
• Are there active alerts which require action?
• Any known issues impacting the performance & availability of a vSAN cluster?
Let us look at each of these dashboard and I will provide a summary of what these dashboards can do for you along with a quick view of the dashboard:
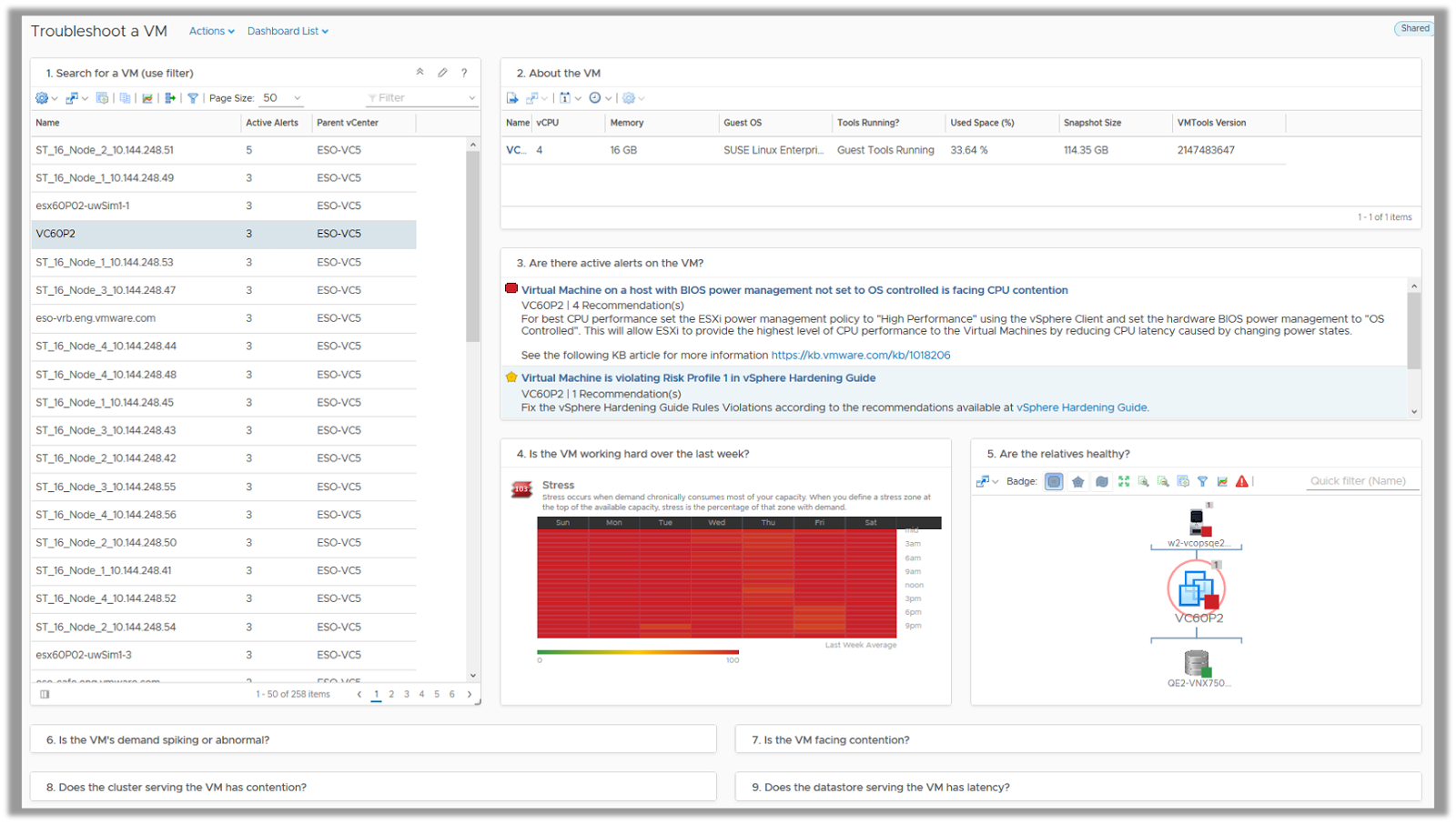
Troubleshoot a VM
The Troubleshoot a VM dashboard helps a VI Administrator to deal with day to day troubleshooting of issues in a virtual infrastructure. While most of the IT issues in an organization are reported at the application layer, this dashboard provides a guided workflow which can help investigate an ongoing or a suspected issue with virtual machines supporting the impacted applications.
You can easily search for a virtual machine by its name or can sort the list of VMs with active alerts on them to start your troubleshooting process. As soon as you select a VM, you can view its key properties to ensure they are configured as per your virtual infrastructure design. Any deviation from standards could cause potential issues. You can view any known alerts, the workload trend of the VM over the past week and if any of the resources serving the virtual machine has any ongoing issue.
The next step in the troubleshooting process allows you to eliminate the major symptoms which might impact the performance or availability of a virtual machine. You can drill down further into the key metrics to find out if the VMs utilization patterns are abnormal or it is contending for basic resources such as CPU, Memory or Disk.
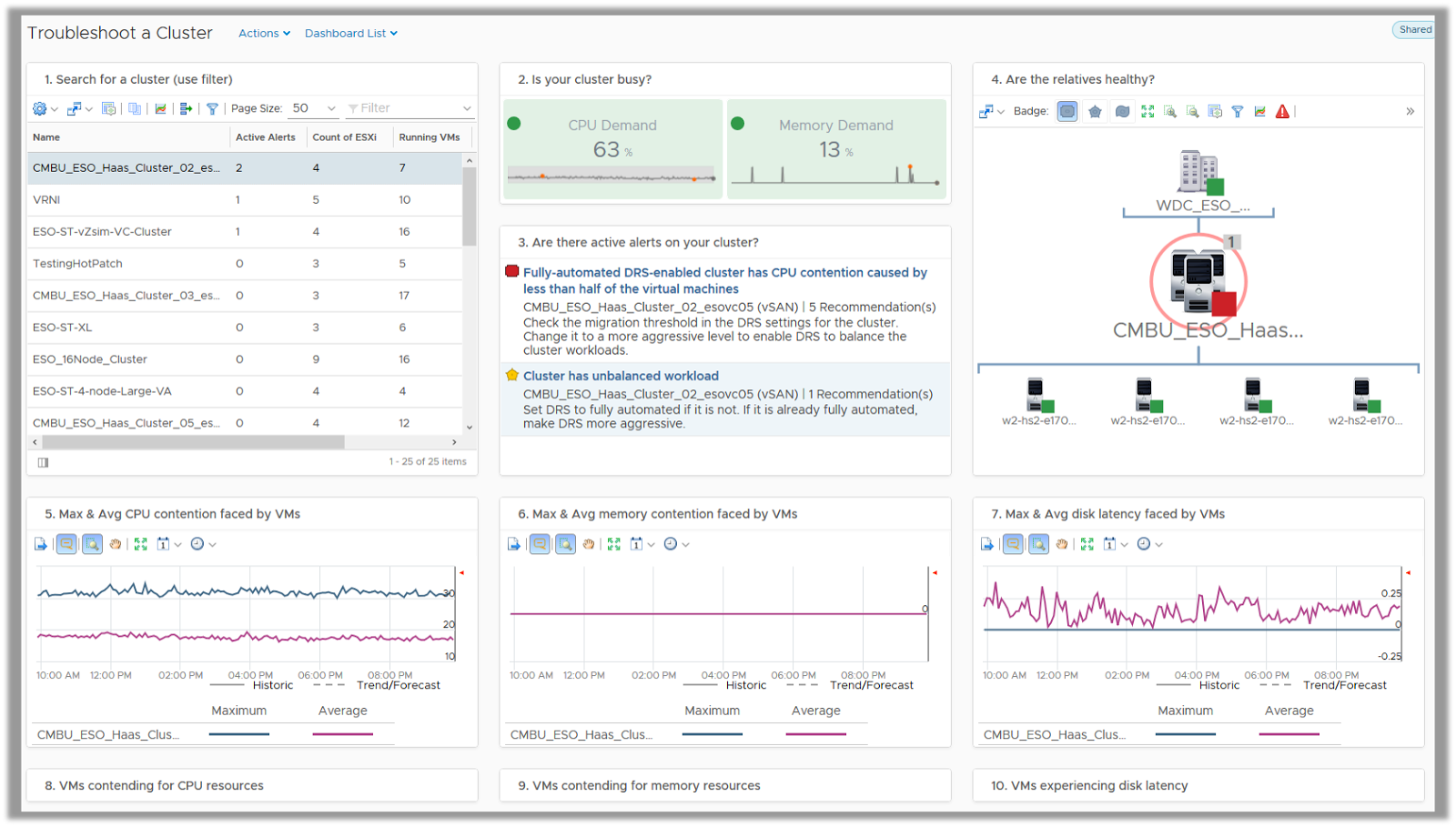
Troubleshoot a Cluster
The Troubleshoot a Cluster Dashboard provides you a guided workflow to identify issues and isolate them easily. You can either start with a cluster which happens to have an issue by using the search option or you can simply sort your clusters with the number of active alerts on them.
On selecting a specific cluster you want to work with, you can see a quick summary of number of hosts participating in that cluster and the VMs being served by them. The dashboard provides you the current and past utilization trends of how hard your cluster is working and what are the known problems on the cluster in form of alerts.
You can easily view the hierarchy of objects related to the cluster and review their status to identify if they are impacted due to the current health of the cluster. You can quickly identify any contention issues by looking at the max and avg. contention faced by the virtual machines on the selected cluster. The dashboard allows you to drill down to specific virtual machines which might be a victim of resource contention and take your next steps in the troubleshooting process to cater to those victims and avoid issues proactively.
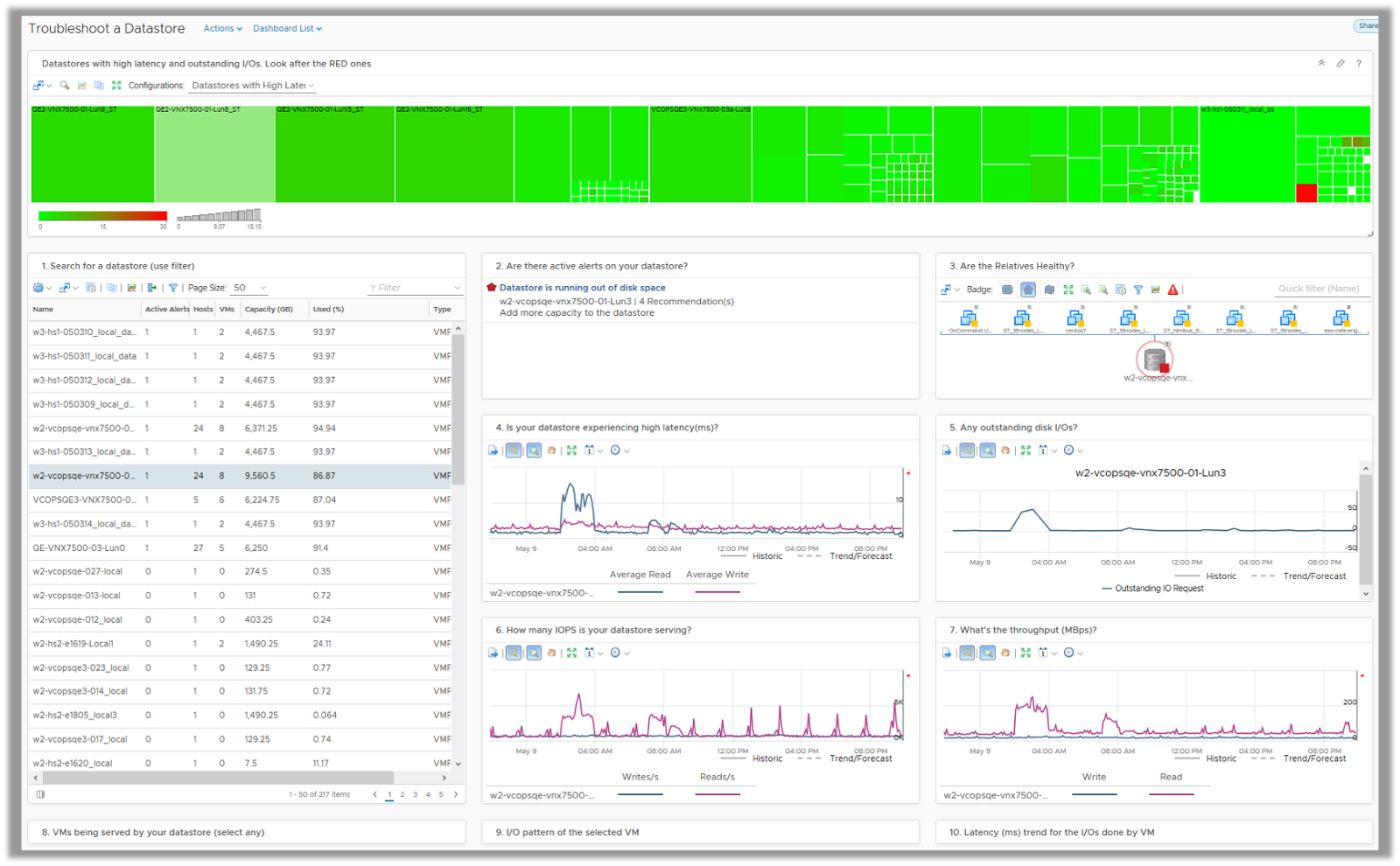
Troubleshoot a Datastore
Troubleshoot a Datastore dashboard helps provide a guided workload to an administrator in order to quickly identify storage issues and act on them. Based on your troubleshooting style you can either start with a Datastore which might be in trouble due to high latency and is showing red on the heatmap or you can search for a Datastore which you have in mind. You can also sort all the datastores with active alerts and start working your way with a Datastore with known problems.
On selecting a datastore you see its current capacity and utilization along with a count of VMs served by that Datastore. The metric charts helps you to view historical trends of key storage metrics such as latency, outstanding IOs and throughput.
The dashboard also lists the virtual machines served by the selected datastore and help you analyze the utilization and performance trends of those virtual machines. If the virtual machines are suffering, the VI administrator can migrate these virtual machines over to other datastores to evenly spread out IO load.
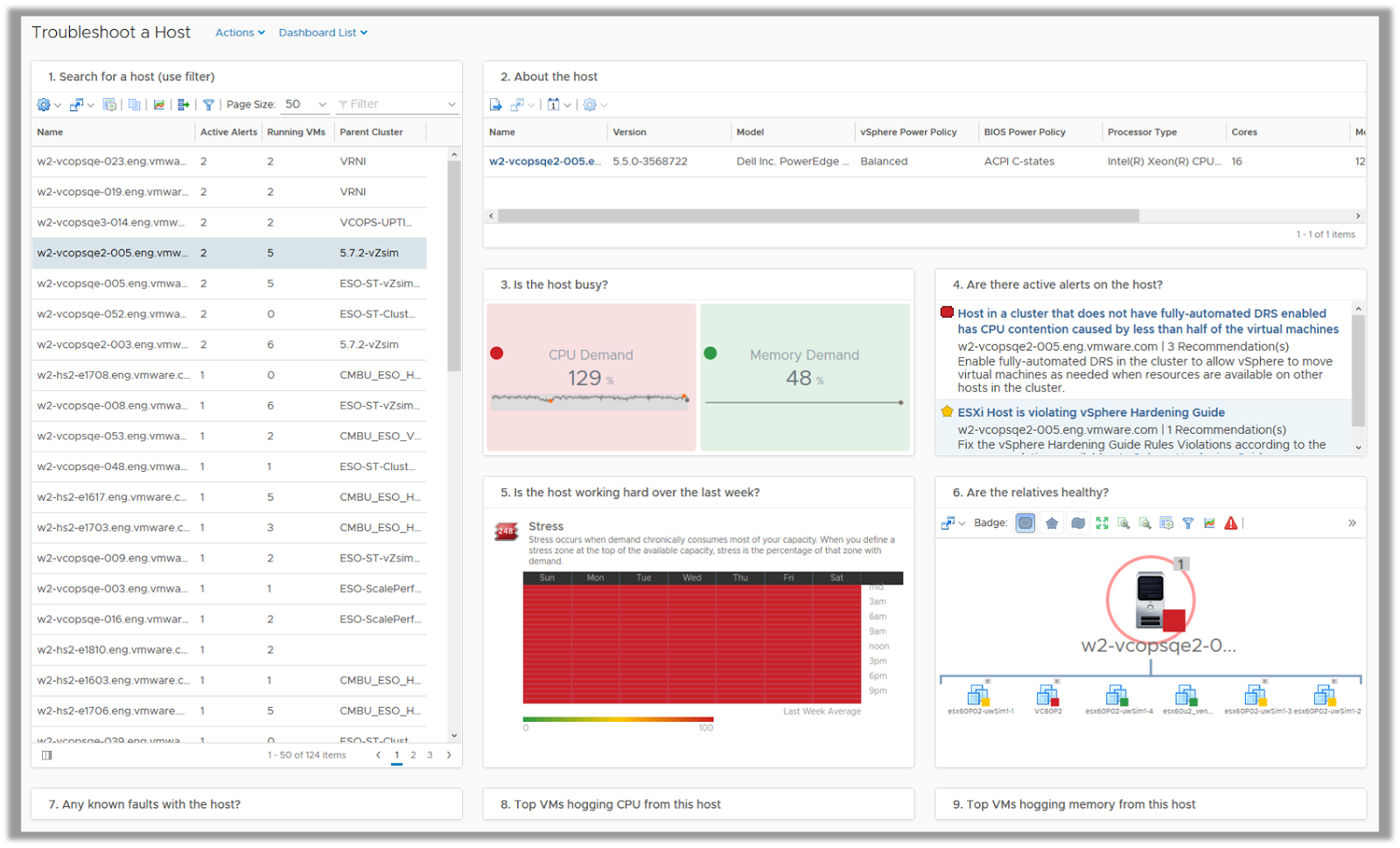
Troubleshoot a Host
Since ESXi servers are the main source of providing resources to a virtual machine, they become extremely critical when it comes to performance and availability. With Troubleshoot a host dashboard, you can either search for specific Host which you have in mind or sort the hosts with active alerts to start your investigation.
As soon as you select a host, you can see the key properties of each of the host to ensure thy are configured as per your virtual infrastructure design. Any deviation from standards could cause potential issues. You can answer some key questions around current and past utilization, workload trends over the last week and if virtual machines served by the host are healthy.
Hardware faults with the hosts can be easily surfaced on this dashboard since it lists all the critical events which might affect the availability of the hosts. If you find a host which is running hot, the next logical step in the troubleshooting process would be to find out the villain virtual machines which might be consuming resources from that host. You can find a list of top 10 virtual machines which are demanding CPU and Memory Resources from the identified host.
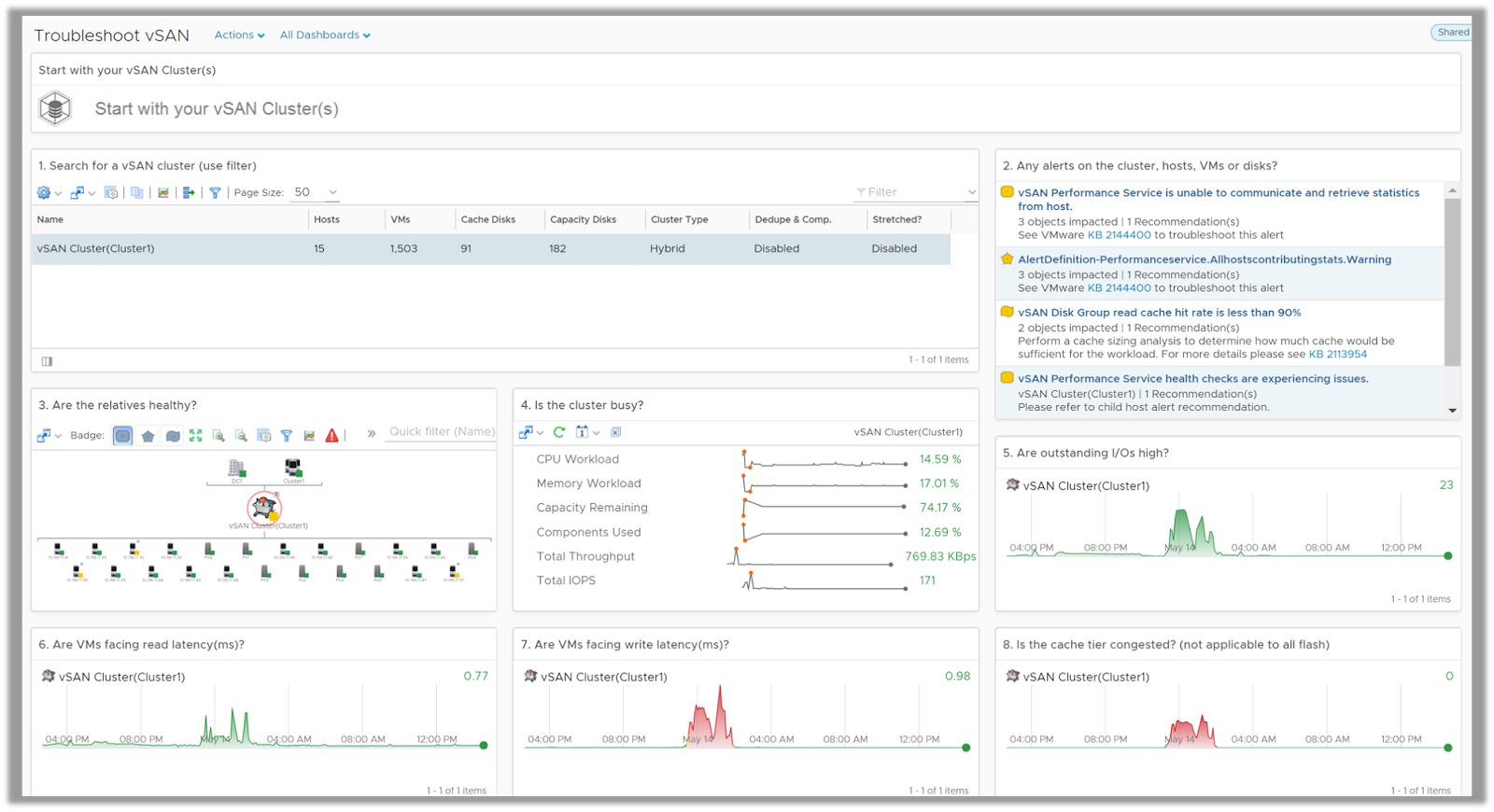
Troubleshoot vSAN
The Troubleshoot vSAN dashboard is designed to help a vSAN administrator step through a guided workflow to investigate potential issues with each layer of vSAN. The dashboard allows you to start with looking at key properties of your vSAN cluster along with the active alerts on any of the cluster components such as hosts, disk groups or the vSAN datastores.
Once you select a cluster, you can list all the known problems with all the objects which are associated to that cluster. This includes, clusters, datastores, disk groups, physical disks and most importantly the virtual machines which are being served by the selected vSAN cluster.
The dashboard then drills down into the key utilization and performance metrics and shows you a trend of how the cluster has been used and has performed over the past 24 hours. You can easily go back in time if you are dealing with historical issues. While most of the problems would be surfaced up at the cluster level, a drill down analysis can be done at the host, disk group or down to the physical disk level.
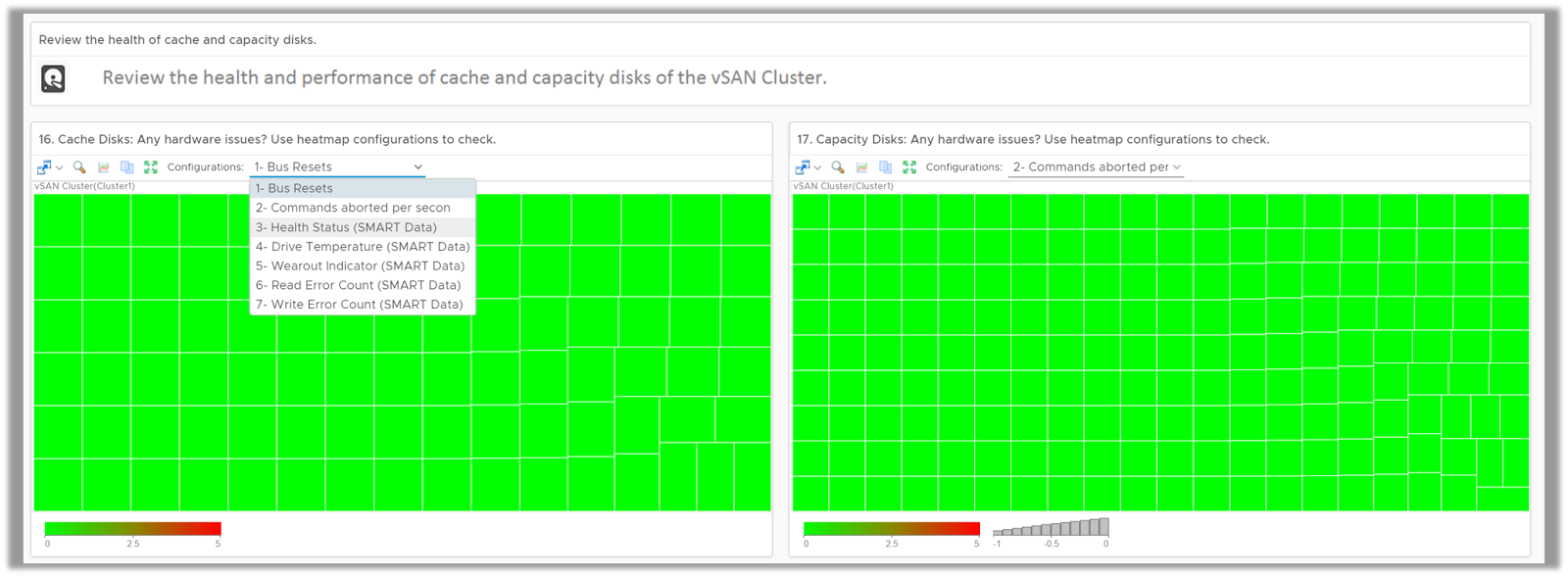
Heatmaps within the dashboard help you answer questions around write buffer usage, cache hit ratio, host configurations and physical issues with capacity and cache disks such as drive wearout, drive temperature and read-write errors.

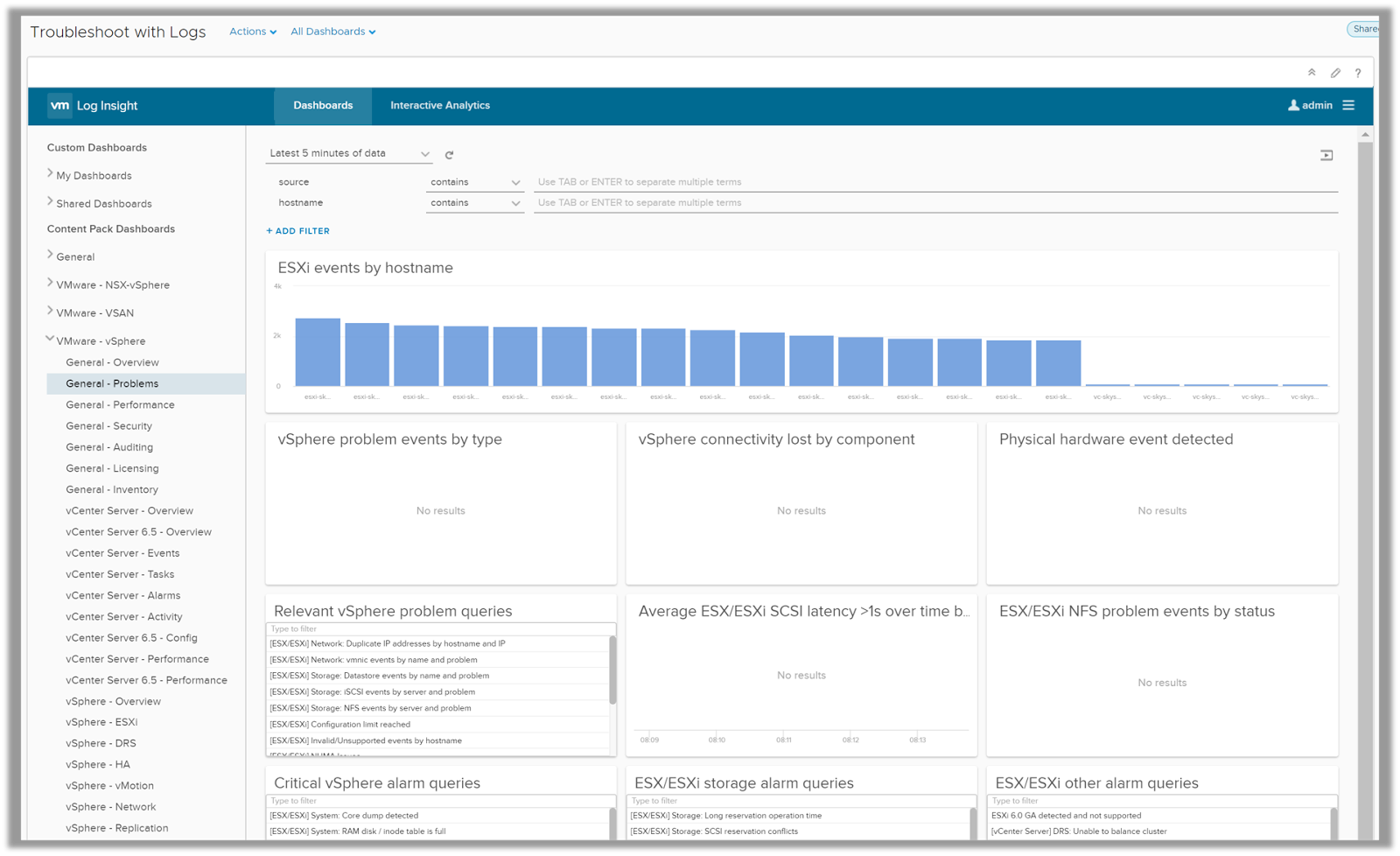
Troubleshoot with Logs
The Troubleshoot with Logs dashboard can be used when you want to investigate an ongoing issue within your virtual infrastructure using the logs. This dashboard helps you to look at predefined views created within Log Insight to answer common questions which can be surfaced through pre-defined queries within Log insight.
With this dashboard, you can correlate metrics and queries within vRealize Operations Manager on a single pane of glass to troubleshoot issues across applications and infrastructure.

In case you are like me, and don’t like to READ. You can see the dashboards in action in this video playlist:
⏩See all dashboards in action here.
More to come.. Stay Tuned!!

{kind=link}