With this part of the series, I will start right from where I left in my
last article. In the previous post, I spoke about the architecture of vROps along with the various services and node types which are available with this release. At the end of that article, I spoke about the benefit of having a cluster like architecture which not only provides scalability to the entire solution, but also allows you to protect the solution by building in resiliency.
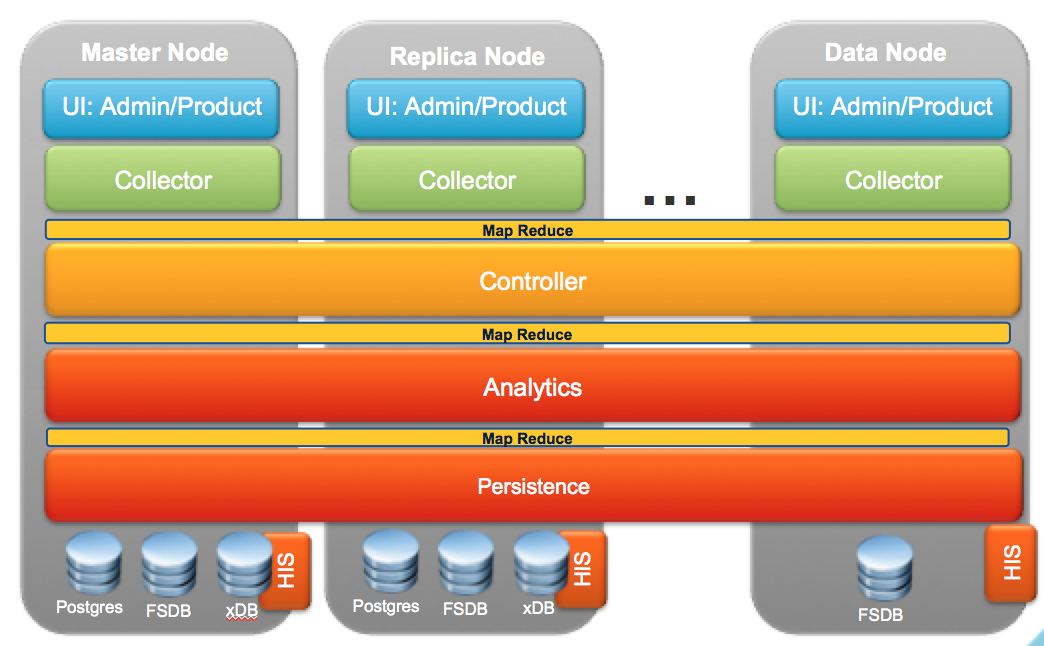
The cluster architecture of vROps is not about scaling the various services within the solution, however it is about making these services modular by using a uniform measure to scale them. This uniform measure is a DATA NODE. Hence, instead of scaling out let’s say just the PERSISTENCE layer by adding more memory, you would basically look at adding a new DATA NODE which will automatically add scale to all the services in an equal amount. This not only makes the solution modular, it also ensures that standardisation is maintained during scale resulting in a predictable and optimised performance.
For ease lets take a scenario where we have One Master Node, One Master Replica and one Data Node as shown in the figure below:-
Taking the above architecture let us discuss a few scenarios which are handled by the vROps cluster for data distribution, redundancy and resiliency.
HOW DATA ARRIVES INTO vROps CLUSTER
The resource will be assigned to one Node and all the analytics work regarding that resource will be done by that node itself. Only in case of failure the standby node which has the replicated data will become the Active Node for that resource.
HOW DATA IS RETRIEVED FROM vROps CLUSTER
With this architecture the data retrieval for ‘HOT DATA’ is extremely fast since the data is in the
“in-memory database” layer of the cluster. Now that we know how the data is collected and retrieved, we can look at various failure scenarios which a vROps cluster can survive.
MASTER NODE FAILURE – If the master node fails, the complete responsibility of the master is taken over by the Master Replica. The Replica gets promoted and ensures that the solution is available at all the time. In case the Master Node failed due to a hardware failure and is back online with the help of vSphere HA, this node will be configured as the Replica Node thereafter.
DATA NODE FAILURE – If the Data Node fails, then the owning resources of that node are promoted on the surviving nodes which have a replica copy of these resources. The new owning node is responsible for collection of data from here onwards. If a data node has failed due to hardware failure and vSphere HA brings it back on a surviving ESXi node in the vSphere cluster, then this node automatically joins the vROps cluster and the data points are synced on this node. If a data node has been out of a cluster for a long time (more than 24 hours), it would be a better idea to re-create that node from the scratch rather than rebuilding/re-syncing the data.
IMPACT ON DATA FLOWS DURING FAILURE – If a node fails while the data is being queried or collected in the vROps cluster, it would not have any impact on data failure or availability as the surviving nodes will serve that data requirement through the replicated resources on them.
The placement of each node of the cluster should be done on a separate ESXi host using anti-affinity DRS rules to ensure that a host failure should not impact more than one Node in the cluster to avoid any data loss / availability issues.
Now that we know how vROps cluster architecture works, in the next part of this series we will have a look at the various deployment models which can come into picture when you plan to deploy vROps 6.0 in your infrastructure.
Till then…. Stay Tuned 🙂
Share & Spread the Knowledge!!



Are there any blogs or posts about the exact process of recovering from a master failure? (when a replica has taken over and been promoted) I was hoping to eventually get rid of the original Master. I've figured out how to move the vCenter adapters to the new Master, but the vRealize Operations Manager adapter is still being managed by the old Master. (current replica)
LikeLike
The replica on failure becomes a master. The correct approach would be to add a new node and configure it as replica from here on.
LikeLike
Hi Sunny,have a query though, I have a clustered vROPs env and have two DCs, DC1 and DC2 and I am adding another data node due to space constraints.Now I have the VLAN configured for the new Data node to DC1 but not DC2.So, will the remote collectors will fail in passing the data to that new Data node and in terms of rebalancing, I have 5 more Data nodes. will the other Nodes be filled up since the new data node isnt in VLAN.Is there any way to restrict Remote collectors to pass data to specific Data node ?
LikeLike