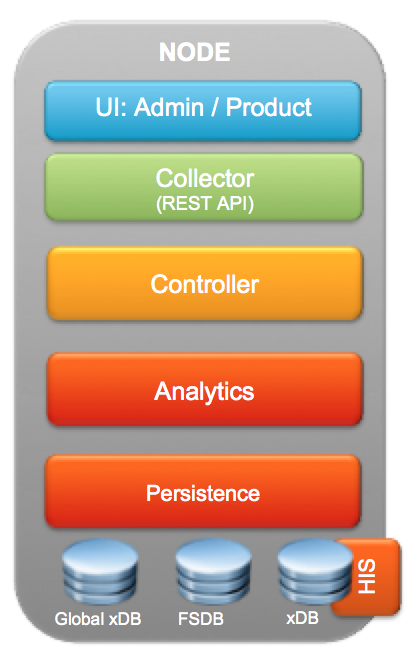
CONTROLLER – The controller here is the brain of the collection & retrieval engine. It is responsible to map the collected data to the right resources and also retrieve data for the requested queries. It also plays a vital role in keeping the remote collectors informed about the changes happening in the system and the work they need to do to ensure consistency of data for all the resources being monitored by the system.
ANALYTICS – The role of the Analytics stack does not change much. This engine ensures that all the patented algorithms within vROps are applied to the collected data and functions such as super-metrics, dynamic threshold calculation, Alerts etc are calculated and then available for viewing, providing recommendations and taking actions.
PERSISTENCE – While all this is happening on the top layer, the mastermind lies in the Persistence layer which gives vROps the performance required for monitoring thousands of objects for which data is collected, stored, analyzed and retrieved at the speed of light. This persistence layer works as a data service layer for all of the above layers & the agility in this data service layer comes from using in-memory database powered by Pivotal Gemfire. Gemfire not only helps with persistence of data, but it also makes vROps CloudScale by easily scaling out the vROps application across multiple nodes. This gives the scalability, performance & availability to the solution which was missing in the previous versions of vROps.
DATABASES – Along with the architectural change vROps 6.0, also has a change in the way the databases work. Let me give you a quick brief as to how these databases function as they are the backbone of the deployment:
- FSDB – The File System Database is available in all the NODES of a vROps 6.0 Cluster deployment. This is where all the collected metrics are stored in the raw format.
- xDB (HIS) – The xDB is where the Historical Inventory Service data is stored. This is available only on the MASTER Node or the first node of the vROps Cluster. This would also be a part of the REPLICA node which is a true copy of the MASTER node for failover purposes.
- GLOBAL xDB – This is where the the user preferences, alerts & alarms stored. This would where all the customization related to vROps would be stored. Like xDB this is available only on the MASTER Node or the first node of the vROps Cluster. This would also be a part of the REPLICA node which is a true copy of the MASTER node for failover purposes.
We will have more clarity once we look at the cluster architecture of vROps 6.0. Let’s now dive in the cluster architecture to understand this in more detail. We will have a look at this graphic to see how a vROps 6.0 cluster can scale out by adding new DATA NODES, and how one of the DATA Nodes can work as a MASTER-REPLICA to ensure that we always have a resilient master in case of the MASTER going down due to hardware or application failure. Remember we have a RAIN architecture and hence the MASTER will always be up and the collection will continue even in case of hardware or application level failures. Here is the Cluster Architecture represented through a graphic:-
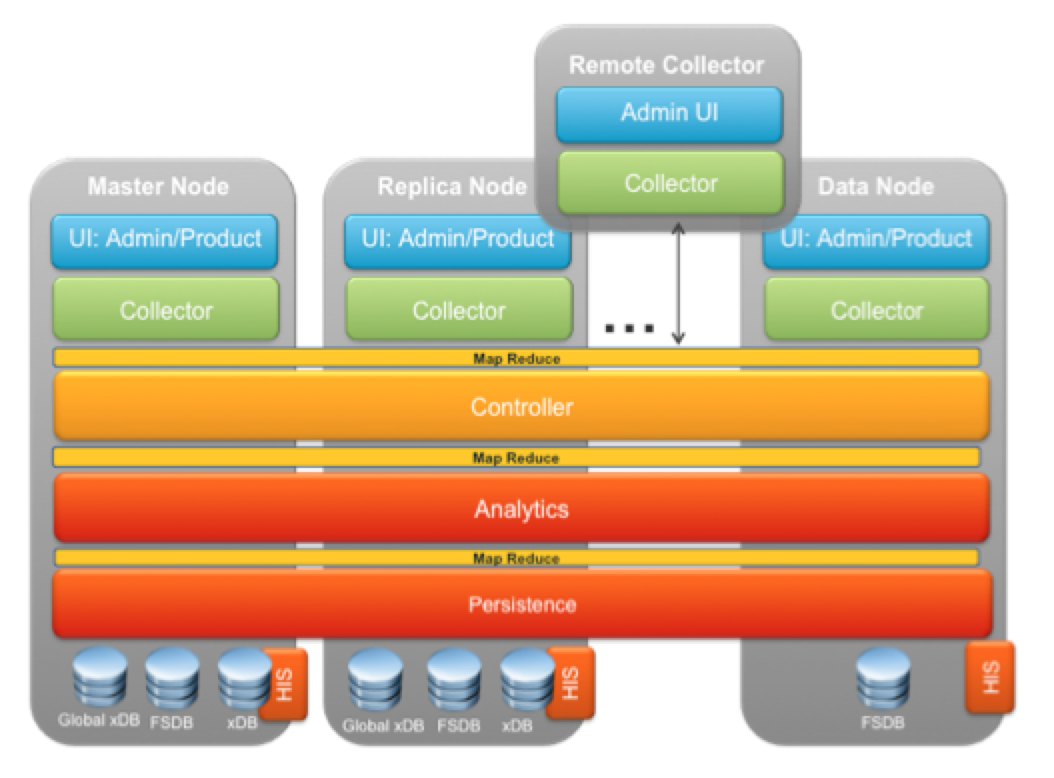
With vROps 6.0, you have the concept of different kinds of nodes which can make up the vROps cluster. Let me give you a brief description about each node type in a cluster:-
MASTER NODE – As the name suggests is the MASTER of the cluster. This is essentially the first node of the cluster i.e. if you plan to build one. I will talk about various deployment models as we move forward in this series. This node has the Global xDB (Postgres), the xDB as well as the FSDB. In essence, this node is where all the customization of your entire vROps solution lies. Things such as user preferences, policies and the entire brain of the solution.
REPLICA NODE – Doing justice to it’s name, the Replica Node also called ‘Master Replica’ is the exact copy of the master node. This is to give resiliency to the solution. In vROps GUI this is identified as enabling High Availability. This node is not doing any work, but just watching the master node at all times and syncing with the node to ensure that it can take its place once the Master Fails.
DATA NODE – Every node which collects data in the vROps cluster is a Data Node. The function of this node is to ensure that it collects the data from you environment based on the adapters which are assigned to this node. This node basically allows you to keep scaling your cluster by adding new nodes.
REMOTE COLLECTOR – The remote collector is not a new concept in vROps, but this is now the only solution to get data from an environment which is not within a LAN. In other words, you have to install a REMOTE COLLECTOR if you need to fetch the data from a remote location into a centralized vROps cluster/node. Good news is that it is the same appliance which you have to install, and just chose collector during the install which makes it a simple install. Collector does not have the CONTROLLER, ANALYTICS or the PERSISTENCE layer since it is not required. It sends the data out to the centralized controller and then the data is treated using the Analytics engine.
With this I will close this article. In my next article, I will give you an overview of how this Cluster Architecture Provides resiliency to vROps solution and ensures that even in case of Node failures or Data Loss, how can vROps can continue to function normally and fetch and load the collected data into the system.
STAY TUNED….
SHARE & SPREAD THE KNOWLEDGE 🙂

This comment has been removed by the author.
LikeLike
Very nice post, explained each layer in well manner.I have very specific query regarding data access. In VCOPS5.8, I was pulling data through sql query from postgres db (alivevm), what is the way to pull data from VROPS6.x ?
LikeLike
Thanks for the info. I'm still wondering what purpose the remote collector serves. I'm designing a solution with a couple of very small remote offices (5-10 VMs each). Will the remote collector help me cache collected data if the connection to the central vROps cluster goes down? If not, what value does it add?
LikeLike
Excellent article. Thanks a lot.
LikeLike
good work Thanks
LikeLike